【Python数据分析与处理 实训04】--- 探索1960 - 2014美国犯罪数据(时间序列处理应用)
本文共 1089 字,大约阅读时间需要 3 分钟。
【Python数据分析与处理 实训04】— 探索1960 - 2014美国犯罪数据(时间序列处理应用)
探索1960 - 2014美国犯罪数据信息
对于下面的数据集进行简单的一些数据的分析训练:

若需要源数据请私信~
1.将数据框命名为crime
crime = pd.read_csv('G:/Projects/pycharmeProject/大数据比赛/泰迪智能科技/data/US_Crime_Rates_1960_2014.csv',sep=",",index_col=0)print(crime) 
2.每一列(columns)的数据类型是什么
print(crime.dtypes)

3.将Year数据类型转换为datatime64
crime['Year'] = pd.to_datetime(crime['Year'])print(crime.dtypes)

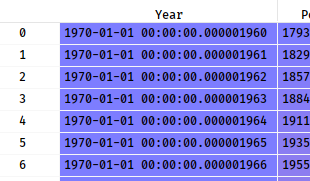
进一步优化:
crime['Year'] = pd.to_datetime(crime['Year'],format="%Y")
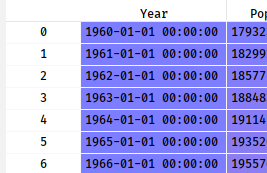
4.将列Year设置为数据框的索引
crime.set_index('Year',inplace=True) 
5.删除名为Total的列
crime.drop('Total',axis=1,inplace=True) 这部分容易出错,参见本人博客:

6.按照Year(每十年)对数据框进行分组并求和
print(crime.resample('10AS').sum()) 这里涉及时间数据的操作运用到了resample方法:在pandas里对时序的频率的调整称之重新采样,即从一个时频调整为另一个时频的操作。
参见本人博客:
大佬文章: pandas官方文档:

7.何时是美国历史上生存最危险的年代
# 计算人口增长率print(crime['Population'].diff()) # 求取一阶差值print(crime['Population'].diff()[1:]) # 取出已知增长人数数据print(crime['Population'].values[:-1]) # 取出60-13年人口数据print(crime['Population'].diff()[1:]/crime['Population'].values[:-1]) # 计算人口增长率print((crime['Population'].diff()[1:]/crime['Population'].values[:-1]).idxmin()) # 得出人口增长率最低的一年



转载地址:http://qghq.baihongyu.com/
你可能感兴趣的文章
LeetCode - 5. 最长回文子串——字符串、动态规划
查看>>
全局锁和表锁 :给表加个字段怎么有这么多阻碍?
查看>>
二分查找与插入排序的结合使用
查看>>
892 三维形体的表面积(分析)
查看>>
279 完全平方数(bfs)
查看>>
875 爱吃香蕉的珂珂(二分查找)
查看>>
第十一届蓝桥杯python组第二场省赛-数字三角形
查看>>
BST中某一层的所有节点(宽度优先搜索)
查看>>
广度优先搜索
查看>>
Eclipse导出项目出现resource is out of sync with the file...错误
查看>>
Dijkstra算法的总结
查看>>
C语言的运算符和表达式
查看>>
Vue实现选项卡功能
查看>>
uni-app请求头中携带token
查看>>
vue中接收后台的图片验证码并显示
查看>>
Vue入门学习笔记(1)
查看>>
趣谈win10常用快捷键
查看>>
数学建模更新12(数学线性规划模型1)
查看>>
Android,SharedPreferences的使用
查看>>
两款用于检测内存泄漏的软件
查看>>